Kaikki me raportointia tehneet olemme pääseet tutustumaan eri liiketoimintayksiköiden omiin raportointiratkaisuihin, joihin tiedot on koottu joko operatiivisista järjestelmistä suoraan tai sitten erillisistä siilomuotoisista tietovarastoista. Tavoitteena on kuitenkin siirtyä yhteiseen tiedontallennusalustaan ja sellaisesta hyvänä esimerkkinä on Data Vault 2.0. (myöhemmin tekstissä DV). Oma kokemukseni DV:stä pohjautuu mallinnukseen. Olen myös suorittanut DV2.0 sertifikaatin, jonka kurssimateriaalin pohjalta tämä artikkeli on rakennettu.
Mikä on Data Vault 2.0?
Data Vault 2.0 on Dan Lindstedtin kehittämä tiedonmallinnusmetodi, joka sisältää arkkitehtuurisen ratkaisun. Metodina mallissa käytetään ketterää kehitysmenetelmää, koska tietovarastoratkaisu rakentuu ajan kanssa, eikä siihen sovellu perinteinen projektityössä käytetty vesiputousmalli. Data Vaultia voi kuvata skaalautuvaksi ja monitasoiseksi, minkä lisäksi se tukee NoSQL syntaksia. Data Vault tukee siis perinteisen relaatiomallin lisäksi muita tietomuotoja. Tietomalli pohjautuu Hub&Spoke malliin. Itse olen verrannut DV:tä legopalikoilla rakentamiseen. Kullekin komponentille on oma värinsä ja näitä palikoita voi yhdistellä vain sovituin säännöin.
DV 2.0 arkkitehtuuri
DV-metodilla rakennettu tietovarasto on kuten tietovarastot yleensä. Siinä on selkeät tietokanta-alueet kullekin toiminnallisuudelle: latausalue (stage) sekä tiedon tallennusalue ja hyödyntämisalue. Latausalueelta tiedonsiirrossa tallennusalueelle voidaan hyödyntää NoSql-lähestymistapaa, mikä tehostaa latausprosessia. Myös tietovaraston avainten muodostus tehdään stagella. Avainten generoinnissa DV2.0 käyttää hajautusavainta, jonka suositusmuoto on MD5. Hajautusavaimella generoidaan luonnollisesta liiketoiminta-avaimesta surrogaattiavain, joka on aina samanmuotoinen tietolähteestä riippumatta. Hajautusavaimella muodostettu, purettu avain on tietomuodosta riippumatta sama. Näin voidaan yhdistää myös eri tietomuotoja toisiinsa, kuten some-dataa ja perinteistä relaatiota. Tallennusalue voi koostua useasta fyysisestä tietoalueesta. Puhutaan virtuaalisesta tietovarastosta, jossa tietomalli rakentuu loogisella tasolla. Vastaavasti voidaan master data-järjestelmästä yhdistää hajautusavaimella tietovarastoon ydintietokäsitteet, joten näitä ei tarvitse tallettaa uudelleen tietovarastoon. Tässä tapauksessa tietovarastoon tallennetaan vain avaimet ja transaktionaalinen tieto.
Tiedon hyödyntämiseen muodostetaan oma kerros, jossa tiedot jäsennellään käyttötarpeen mukaan. DV:ssä käytetään termiä info mart, joita voivat olla esimerkiksi kuutiot.
DV 2.0 tietomalli
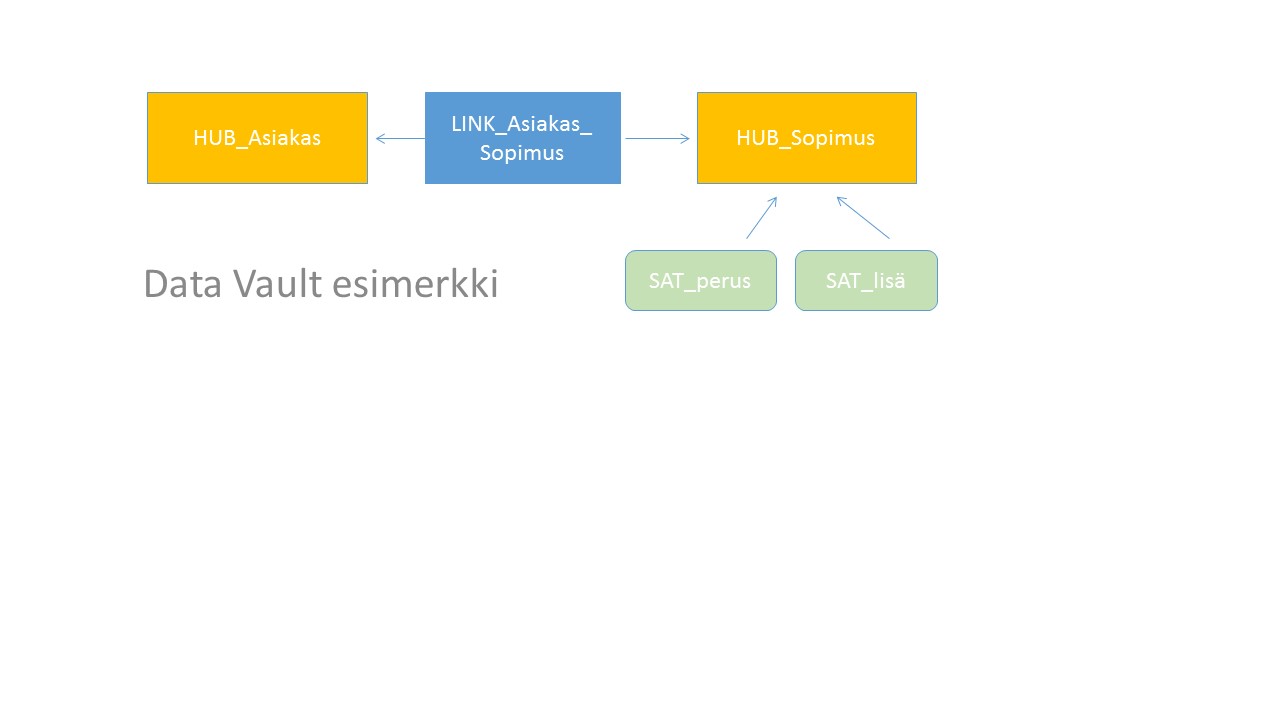
Standardoitu tietomallinnusmetodi on saatu sillä aikaan, että on käytössä vain muutamia peruskomponentteja. Näitä ovat HUB ( Liiketoimintakäsite) , SATELLITE ( käsitettä kuvaavat tiedot) ja LINK (käsitteiden yhdistäminen). Koska maailma ei ole mustavalkoinen, niin käytössä on myös muutamia muita, kuten Bridge, jolla voidaan yhdistää usempi Hub toisiinsa. Jopa DW mallinnuksen isä Bill Inmon on hyväksynyt Data Vaultin tietomalliksi omaan tietovarastointimetodiinsa.
Hub
Hub on kaiken perusta. Hub on yhdistettävissä liiketoiminnan käsitemallin käsitteisiin, esim asiakas, tuote ja toimittaja. Hubiin kootaan vain käsitteeseen liittyvä hajautusavain sekä voimassaolotieto. Hubeissa tietoa ei ylläpidetä, niihin voidaan tehdä vain lisäyksiä. Hubit yhdistetään toisiinsa Linkeillä.
Satellite
Varsinainen käsitteitä kuvaava tietosisältö muodostetaan satelliitteihin. Yhteen hubiin voi kuulua useita satelliitteja tietosisällön ominaisuuksien mukaan. Satelliitit voi muodostaa esimerkiksi sen mukaan, miten usein tietoa päivitetään. Eri lähdejärjestelmistä saatava tieto voidaan myös koota omiin satelliitteihinsa. Yleisesti ottaen asiakkaan nimi muuttuu harvemmin kuin osoitetieto, jolloin asiakkaan pysyvät perustiedot ja muuttuvat tiedot voisivat olla omia satelliittejaan. Itseasiassa tähän rakenteeseen pohjautuu IBM:n IAW-malli, johon olen tutustunut vakuutusmaailmassa. Muuttuvat tiedot päivittyvät eri sykleillä, ja siksi tarvitaan useita satelliitteja kuvaamaan esimerkiksi osoitetietoja tai ostokäyttäytymistä. Teknisesti satelliitti on paikka, jonne luodaan uusia tietoja ja tehdään ylläpitoa tai joka merkitään poistettavaksi. Itse tietovarastosta ei fyysisesti poisteta tietoja. Perusmallissa satelliittien välillä ei voi olla suoria yhteyksiä, vaan satelliitit yhdistyvät toisiinsa aina Hubin kautta. Satelliiteista muodostetaan tiedonhyödyntämiskerros raportointia, analysointia ja jatkojalostusta varten. Esimerkiksi asiakkaan nimi ja osoitetiedot yhdistetään samaan tietokokonaisuuteen, raportointimarttiin.
Tietovaraston perustehtävän tiedon yhdenmukaistamisen näkökulmasta Hub-satelliitti – rakenteen etuna on se, että kaikki samaan käsitteeseen liittyvät tietoalkiot saadaan yhteiseen avainulottuvuuteen ja kunkin näistä tietosisältö saadaan hallittua omassa tietorakenteessaan eikä yhdessä ja samassa taulussa. Esimerkiksi tuoterakenteet, kooditukset ja luokittelut vaihtelevat usein operatiivisissa järjestelmissä liiketoiminnan vaatimusten mukaisesti. Ylläpidollisesti Hub-satelliitti-rakenne vähentää tarvittavaa tallennustilaa. Yksittäisen tiedon muuttuessa muutetaan vain kyseistä satelliittia eikä koko tietorakennetta avaimineen. Koodistojen yhtenäistäminen tehdään raportointimarteissa.
Link
Link nimensä mukaisesti yhdistää eli linkittääeri käsitteet toisiinsa. Link –rakenne mahdollistaa sen, ettei liiketoiminnan mallinnuksessa tarvitse vielä miettiä ns. monen suhde moneen -yhteyksien purkamista vaan se tapahtuu Link-taulujen avulla. Jokaisessa linkissä on sillä yhdistettävien Hubien avaintiedot ja näiden välisen yhteyden voimassaolo. Linkillä voi olla myös muutamia omia attribuutteja. Esimerkki linkistä voisi olla Link_Asiakas_Tuote, jossa linkillä yhdistetään Hub_Asiakas ja Hub_Tuote. Linkkeihin kohdistuu vastaava ylläpitokäytäntö kuin Hubeihin, toki niin että, jos jokin yhteys kahden hubin välillä poistuu, niin linkki vanhennetaan muttei poisteta.
Tehokas tapa laajentaa tietovarastoa
Tietovarastojen perusongelma on aina ollut, miten sitä saadaan laajennettua ilman, että olemassaolevat rakenteet kärsivät. Raportoinnissa tämä on näkynyt mm. organisaatiomuutosten tai yritysfuusioiden yhteydessä. Tällöin asiakas-, tuote- jne. koodistot ovat muuttuneet ja on tullut lisää transaktionaalista dataa. Jos yrityksen masterdata-ratkaisu ei tue näitä liiketoiminnan muutoksia ongelmat ovat kasaantuneet tietovaraston ja raportoinnin harteille. DV-ratkaisu mahdollistaa sen, että näitä muutoksia voidaan tehdä joko lisäämällä tai muuttamalla satelliitteja tai lisäämällä uusia Hubeja linkeillä olemassaoleviin Hubeihin.
Ajoketjut syntyvät standardisäännöillä. Ensin ladataan Hubit, koska näihin kohdistuu vain insert- proseduureja ja niiden avulla varmistetaan että kaikki tarvittavat avaimet ovat käytössä. Kun Hubit on ladattu, voidaan ladata rinnakkain sekä Satelliitteja että Linkkejä. Uudet ajoketjut lisätään näille kuuluville paikoille ajoketjussa eikä mikään aikaisempi ajo mene rikki.
DV2.0 kehitysmetodina on agile.
Standardoidussa DV2.0 kehitysmetodina on ketterät-menetelmät. Ketteryys toimii hyvin, koska DV:tä voidaan rakentaa itsenäisissä osissa. Ideaalitilanne on se, että yhdessä liiketoiminnan kanssa priorisoidaan ja vaiheistetaan kehitys ja yksittäisen kehitysvaiheen osalta toimitaan ketterästi. Liiketoiminnalla tulee olla selkeät tavoitteet, jotta hanke voidaan jakaa osakokonaisuuksiin. Utopiaa on, että olisi tietovarastohanke, joka tehdään määrittelystä tuotantoonottoon käyttäen pelkästään ketteriä menetelmiä.
Digitalisaatio, IoT, Some ja muut tietomuodot.
Kun valmistuin datanomiksi käytettiin vielä osittain verkko- ja hierakiatietokantoja ja relaatiot olivat vasta lyömässä läpi. Tänä päivänä nuo relaatiot ovat edelleen tietokantojen pohjana, mutta nyt on arkipäivää hyödyntää muitakin tietomuotoja. Perinteisen tietovaraston osalta tästä on aiheutunut melkoista päänvaivaa. Miten saadaan vaikkapa xml-muotoinen tietosisältö purettua tiedon hyödyntämistarpeiden mukaan? DV tarjoaa tähän ratkaisun. Koska DV 2.0 tarjoaa tehokkaan avainhallinnan hajautusavaimella, voidaan tietojen tallennuspaikat hajasijoittaa. Esimerkiksi voidaan seurata asiakkaan tekemiä verkkokauppaostoksia hyödyntämällä asiakastunnusta ja weblogitusdataa ilman, että tietoja pitää yhdistää samaan tietokantaan.
Miksi DV?
Kun minulta on kysytty, miksi valita DV, olen vastannut, miksi ei? Tiedonhallinnan näkökulmasta en löydä sille vastaehdokasta. Liiketoiminta puolestaan näkee tietovaraston siitä näkökulmasta, että raportit tulevat ajallaan ja oikein. Liiketoiminnan kanssa yhdessä myös lähdetään tekemään tietovaraston käsitemallia. Nämä kaksi rajapintaa ovat DV:n vahvuuksia. Koska DV muodostuu liiketoimintakäsitteistä, voidaan liiketoiminnan mallinnus tehdä jäsennellysti ja lopputulos on kokoajan näkyvillä. Liiketoiminta-alueiden mallintamista voidaan priorisoida ja jakaa. Käsitemallin laajennukset eivät aiheuta tietovarastossa mammuttiprojekteja, kun uudet käsitteet saadaan nivottua aikaisempiin yhdistämällä ne linkeillä. Uudet tietosisällöt taas sijoitetaan näille mallinnettuihin satelliitteihin. Tiedot valuvat sen jälkeen DV:n rakenteita pitkin kohti raportointia ilman, että pitäisi lähteä rakentamaan koko tietovarastoa uudelleen. Oikeelliseksi ne saadaan, kun tunnetaan liiketoiminnan sisältö ja raportoinnin käyttötarkoitus ja se on sitten oma tarinansa.
 Minna Oksanen on pohjakoulutukseltaan datanomi, jonka intohimona jo opiskellessa oli käsitemallinnus. Hän on toiminut viimeiset 20 vuotta erilaisissa tiedonhallinnan tehtävissä pääsääntöisesti Bi-alueella, mutta myös master data on hänelle tuttua.
Minna Oksanen on pohjakoulutukseltaan datanomi, jonka intohimona jo opiskellessa oli käsitemallinnus. Hän on toiminut viimeiset 20 vuotta erilaisissa tiedonhallinnan tehtävissä pääsääntöisesti Bi-alueella, mutta myös master data on hänelle tuttua.